基本概念
1.字符操作,区别于字符串
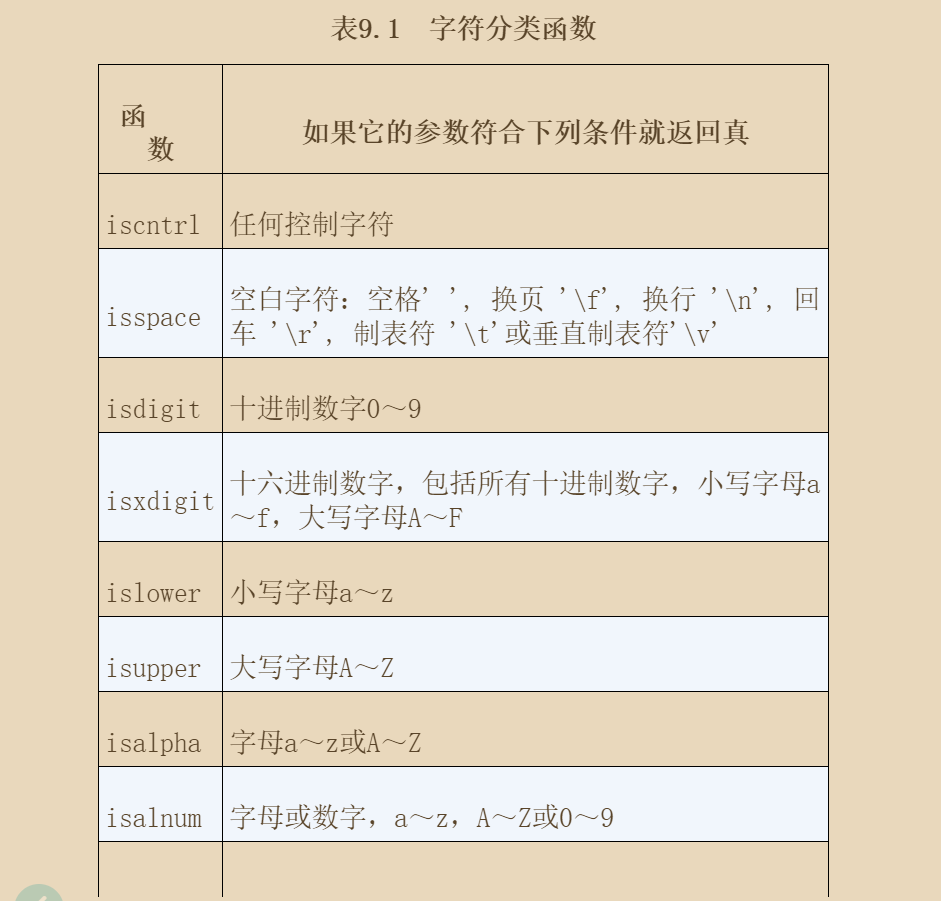
标准库包含了两组函数,用于操作单独的字符,它们的原型位于头文件ctype.h。
字符分类

2.字符转换
转换函数把大写字母转换为小写字母或者把小写字母转换为大写字母。
1 | int tolower( int ch );//tolower函数返回其参数的对应小写形式 |
如果函数的参数并不是一个处于适当大小写状态的字符(即toupper的参数不是小写字母或tolower的参数不是个大写字母),函数将不修改参数直接返回。
直接测试或操纵字符将会降低程序的可移植性。例如,考虑下面这条语句,它试图测试ch是否是一个大写字符。
这条语句在使用ASCII字符集的机器上能够运行,但在使用EBCDIC字符集的机器上将会失败。另一方面,下面这条语句
无论机器使用哪个字符集,它都能顺利运行。
3.内存操作
处理字符串内部包含NUL的字符。

1.memcpy从src的起始位置复制length个字节到dst的内存起始位置。你可以用这种方法复制任何类型的值,第3个参数指定复制值的长度(以字节计)。如果src和dst以任何形式出现了重叠,它的结果是未定义的。
1 | char temp[SIZE], values[SIZE]; |
如果两个数组都是整型数组该怎么办呢?
1 | memcpy( temp, values, sizeof( values ) ); |
前两个参数并不需要使用强制类型转换,因为在函数的原型中,参数的类型是void型指针,而任何类型的指针都可以转换为void\型指针.
2.memmove函数的行为和memcpy差不多,只是它的源和目标操作数可以重叠。memmove通常无法使用某些机器所提供的特殊的字节-字符串处理指令来实现,所以它可能比memcpy慢一些。但是,如果源和目标参数真的可能存在重叠,就应该使用memmove,如下例所示:

3.memcmp对两段内存的内容进行比较,这两段内存分别起始于a和b,共比较length个字节。这些值按照无符号字符逐字节进行比较,函数的返回类型和strcmp函数一样——负值表示a小于b,正值表示a大于b,零表示a等于b。由于这些值是根据一串无符号字节进行比较的,所以如果memcmp函数用于比较不是单字节的数据如整数或浮点数时就可能给出不可预料的结果。
4.memchr从a的起始位置开始查找字符ch第1次出现的位置,并返回一个指向该位置的指针,它共查找length个字节。如果在这length个字节中未找到该字符,函数就返回一个NULL指针。
5.memset函数把从a开始的length个字节都设置为字符值ch。
1 | memset( buffer, 0, SIZE );//把buffer的前SIZE个字节都初始化 |
4.结构体声明


这两个声明被编译器当作两种截然不同的类型,即使它们的成员列表完全相同。因此,变量y和z的类型和x的类型不同,所以下面这条语句
1 | z = &x;//非法的 |

这个技巧和声明一个结构标签的效果几乎相同。区别在于Simple现在是个类型名而不是个结构标签,所以后续的声明可能像下面这个样子:
1 | Simple x; |
5.结构体访问

等价于

->操作符(也称箭头操作符)。
和点操作符一样,箭头操作符接受两个操作数,但左操作数必须是一个指向结构的指针 。
箭头操作符对左操作数执行间接访问取得指针所指向的结构,然后和点操作符一样,根据右操作数选择一个指定的结构成员。
但是,间接访问操作内建于箭头操作符中,所以我们不需要显式地执行间接访问或使用括号。
- 结构体中应该相同的变量类型生命在一起,这样可以减少因对齐带来的空间损失;但为了可读性和可维护性可以不对结构体成员进行重排。
例如:
1 | struct ALIGN { |
重排后:
1 | struct ALIGN2 { |
6.sizeof操作符
- sizeof操作符能够得出一个结构的整体长度,包括因边界对齐而跳过的那些字节。
- 如果你必须确定结构某个成员的实际位置,应该考虑边界对齐因素,可以使用offsetof宏(定义于stddef.h)。
函数原型:
1 | offsetof( type, member ) |
type就是结构的类型,member就是你需要的那个成员名。
表达式的结果是一个size_t值,表示这个指定成员开始存储的位置距离结构开始存储的位置偏移几个字节。
例如:
1 | offsetof( struct ALIGN, b ) //返回值是4 |
7.结构体调用
- C语言的参数传值调用方式要求把参数的一份拷贝传递给函数,所以调用结构时使用指针效率更高。
- 向函数传递指针的缺陷在于函数现在可以对调用程序的结构变量进行修改。如果我们不希望如此,可以在函数中使用const关键字来防止这类修改。
例如:
1 | void print_receipt( register Transaction const *trans ); |
什么时候你应该向函数传递一个结构而不是一个指向结构的指针呢?很少有这种情况。
只有当一个结构特别的小(长度和指针相同或更小)时,结构传递方案的效率才不会输给指针传递方案。
但对于绝大多数结构,传递指针显然效率更高。
如果你希望函数修改结构的任何成员,也应该使用指针传递方案。
8.位段
位段的声明和结构类似,但它的成员是一个或多个位的字段。这些不同长度的字段实际上存储于一个或多个整型变量中。
位段的声明和任何普通的结构成员声明相同,但有两个例外。
首先,位段成员必须声明为int、signed int或unsigned int类型。
其次,在成员名的后面是一个冒号和一个整数,这个整数指定该位段所占用的位的数目。

- 注重可移植性的程序应该避免使用位段。
这个声明取自一个文本格式化程序,它可以处理多达128个不同的字符值(需要7个位)、
64种不同的字体(需要6个位)以及0到524 287个单位的长度。
使用位段的好理由
它能够把长度为奇数的数据包装在一起,节省存储空间。
当程序需要使用成千上万的这类结构时,这种节省方法就会变得相当重要。
另一个使用位段的理由是由于它们可以很方便地访问一个整型值的部分内容。
9.联合
联合的所有成员引用的是内存中的相同位置 。

在一个浮点型和整型都是32位的机器上,变量fi只占据内存中一个32位的字。如果成员f被使用,这个字就作为浮点值访问;如果成员i被使用,这个字就作为整型值访问。

现在,对于整型变量,你将在type字段设置为INT,并把整型值存储于value.i字段。对于浮点值,你将使用value.f字段。当以后得到这个变量的值时,对type字段进行检查决定使用哪个值字段。这个选择决定内存位置如何被访问,所以同一个位置可以用于存储这三种不同类型的值。注意编译器并不对type字段进行检查证实程序使用的是正确的联合成员。维护并检查type字段是程序员的责任。
在一个成员长度不同的联合里,分配给联合的内存数量取决于它的最长成员的长度。
如果这些成员的长度相差悬殊,当存储长度较短的成员时,浪费的空间是相当可观的。在这种情况下,更好的方法是在联合中存储指向不同成员的指针而不是直接存储成员本身。所有指针的长度都是相同的,这样就解决了内存浪费的问题。
联合的初始化


